Linear Probing
Chaining essentially makes use of a second dimension to handle collisions. Chaining is an example of a closed addressing. With closed addressing collision resolution methods use the hash function to specify the exact index of where the item is found. We may have multiple items at the index but you are looking at just that one index.
This is not the case for linear probing. Linear Probing only allows one item at each element. There is no second dimension to look. Linear probing is an example of open addressing. Open addressing collision resolution methods allow an item to be placed at a different spot other than what the hash function dictates. Aside from linear probing, other open addressing methods include quadratic probing and double hashing.
With hash tables where collision resolution is handled via open addressing, each record actually has a set of hash indexes where they can go. If the first location at the first hash index is occupied, it goes to the second, if that is occupied it goes to the third etc. The way this set of hash indexes is calculated depends on the probing method used (and in implementation we may not actually generate the full set but simply apply the probing algorithm to determine where the "next" spot should be).
Linear probing is the simplest method of defining "next" index for open address hash tables. Suppose hash(k) = i, then the next index is simply i+1, i+2, i+3, etc. You should also treat the entire table as if its round (front of array follows the back). Suppose that m represents the number of slots in the table, We can thus describe our probing sequence as:
Method 1:
Insertion
The insertion algorithm is as follows:
- use hash function to find index for a record
- If that spot is already in use, we use next available spot in a "higher" index.
- Treat the hash table as if it is round, if you hit the end of the hash table, go back to the front
Each contiguous group of records (groups of record in adjacent indices without any empty spots) in the table is called a cluster.
Searching
The search algorithm is as follows:
- use hash function to find index of where an item should be.
- If it isn't there search records that records after that hash location (remember to treat table as cicular) until either it found, or until an empty record is found. If there is an empty spot in the table before record is found, it means that the the record is not there.
- NOTE: it is important not to search the whole array till you get back to the starting index. As soon as you see an empty spot, your search needs to stop. If you don't, your search will be incredibly slow
Removal
The removal algorithm is a bit trickier because after an object is removed, records in same cluster with a higher index than the removed object has to be adjusted. Otherwise the empty spot left by the removal will cause valid searches to fail.
The algorithm is as follows:
- find record and remove it making the spot empty
- For all records that follow it in the cluster, do the following:
- determine the hash index of the record
- determine if empty spot is between current location of record and the hash index.
- move record to empty spot if it is, the record's location is now the empty spot.
Example:
Suppose we the following 7 keys and their associated hash indices. Let us then insert these 5 keys from k1 to k5 in that order.
| Key | Hash Index |
|---|---|
| k1 | 8 |
| k2 | 7 |
| k3 | 9 |
| k4 | 1 |
| k5 | 8 |
| k6 | 9 |
| k7 | 8 |
Insert keys k1 to k4
All four keys have the different hash indexes and thus, no collisions occur, they are simply placed in their hash position.

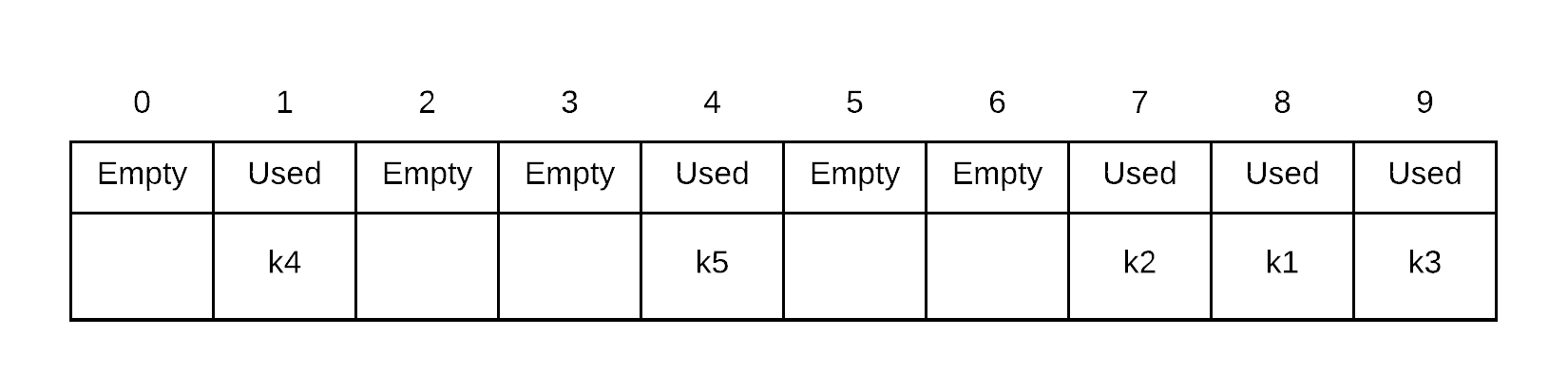
Insert k5. probe sequence of k5 is . Thus, we place k5 into index 0 because 8, 9 and 0 are all occupied

Suppose we then decided to do a search for k6. k6 does not exist, so the question is when can we stop. k6's probe sequence is: . We begin looking at the first probe index 9. We proceed until we get to index 2. Since index 2 is empty, we can stop searching

Search for k5. If we were to search for something that is there, this is what would happen. Probe sequence for k5 is . Thus, we would start search at 8, we would look at indices 8,9,0, and 1. At index 1 we find k5 so we stop

Now, lets remove a node.
A cluster is a group of records without any empty spots. Thus, any search begins with a hashindex within a cluster searches to the end of the cluster.
Currently there is one big cluster from index to 7 to index 1 inclusive.
Suppose we removed k3. If we did this, our one big cluster would be split into two smaller clusters. This is actually a good thing as search stops on first empty spot. So the only question really is whether each record in the group that follows the removed records are in the correct cluster (the groups before the removed record is always in the correct spot.
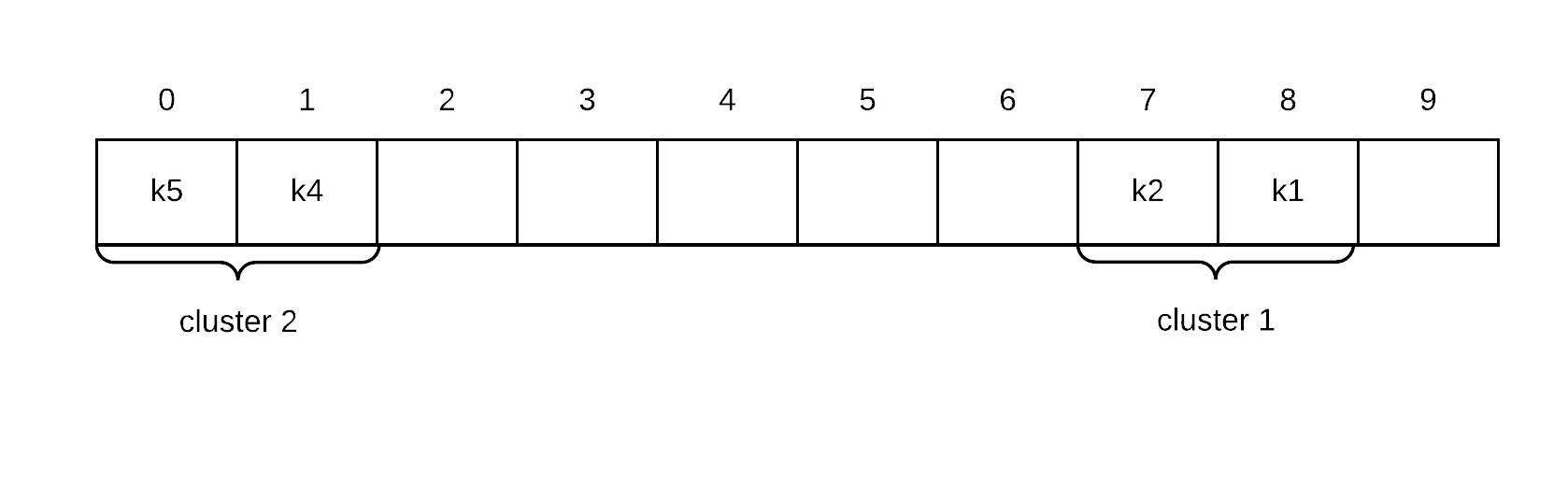
So we go through the remaining records in the cluster and use the hashindex of each key to determine if its in the correct cluster. If it is in the wrong cluster we move. it
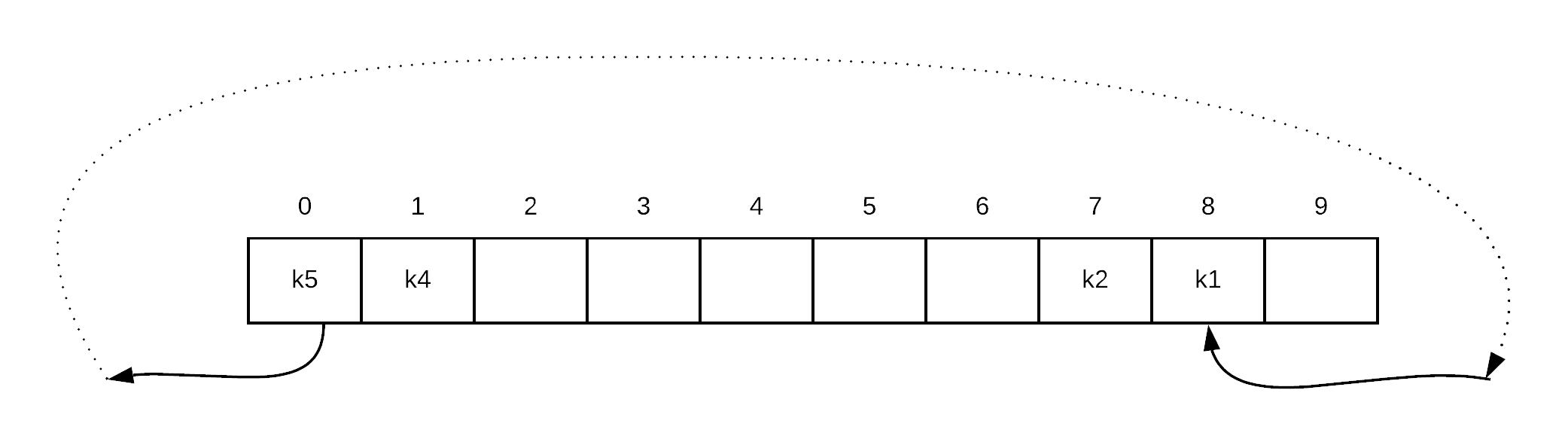
Continuing with example, we look at k5. k5 should actually go in 8, so the record is in the wrong side of the empty spot, so what we do is move the record into the empty spot, make k5's spot the empty spot and continue.
We test k4 and its in the correct side of the empty spot so we leave it alone
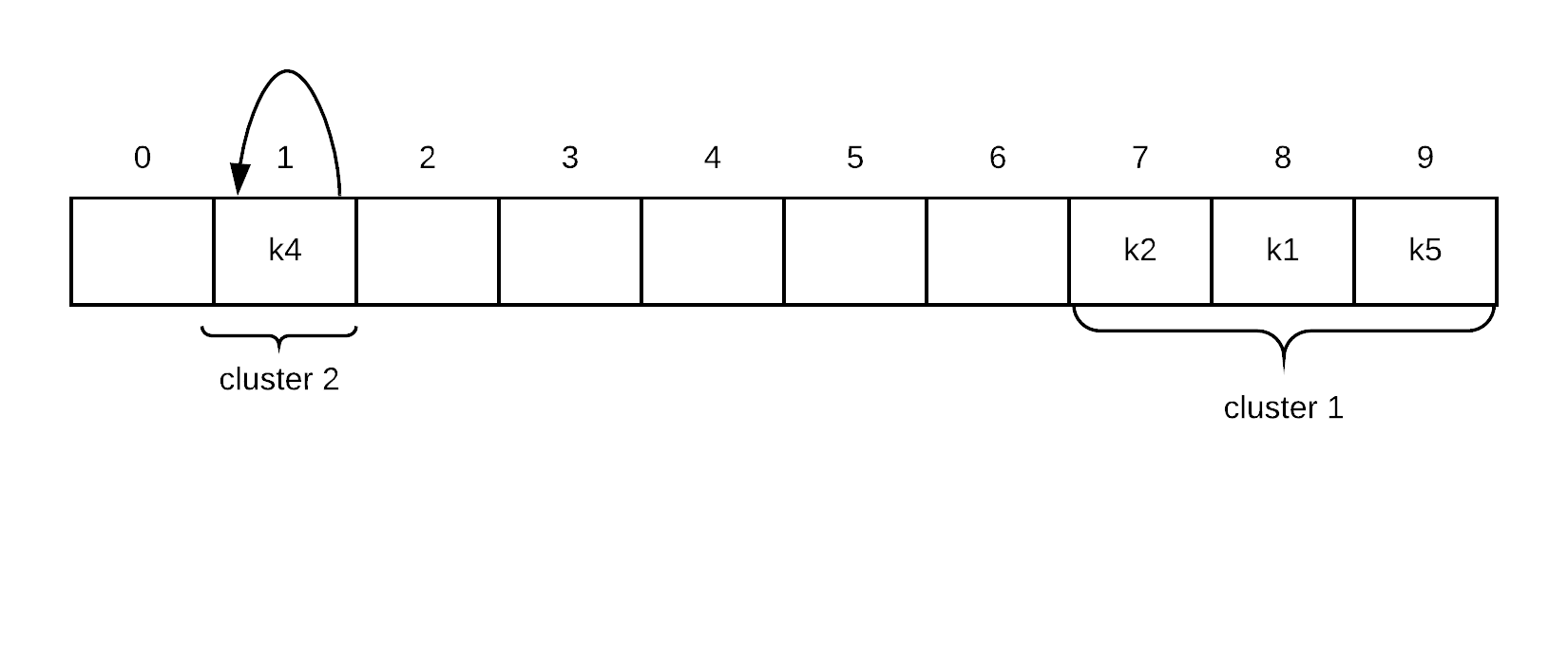
We finish processing the records within the cluster so we are done.
Method 2: Tombstoning
Tombstoning is a method that is fairly easy to implement. It requires each element to not only store the record, but also a status of element. There are three statuses:
- Empty - nothing has ever been inserted into this spot
- Used/Occuppied - a record is stored here
- Deleted - something was here but it has been deleted. Note this is NOT exactly the same as empty. You will see why in a moment.
Insertion
- If it is not there, start looking for the first "open" spot. An open spot is the first probe index that is either deleted or empty.
Searching
The search algorithm is as follows:
- use hash function to find index of where an item should be.
- Check to see if the item's key matches that of key we are looking for
- If it isn't there search for key-value pairs in the "next" slot according to the probing method until either it found, or until an we hit an empty slot.
- NOTE: it is important not to search the whole array till you get back to the starting index. As soon as you see an empty slot, your search needs to stop. If you don't, your search will be incredibly slow for any item that doesn't exist.
Note that only empty slots stop searching not deleted slots
Removal
The removal algorithm is as follows:
- search for the record with matching key.
- If you find it, mark the spot as deleted
Suppose we the following 6 keys and their associated hash indices (these are picked so that collisions will definitely occur). Let us then insert these 5 keys from k1 to k5 in that order.
| Key | Hash index |
|---|---|
| k1 | 8 |
| k2 | 7 |
| k3 | 9 |
| k4 | 7 |
| k5 | 8 |
| k6 | 9 |
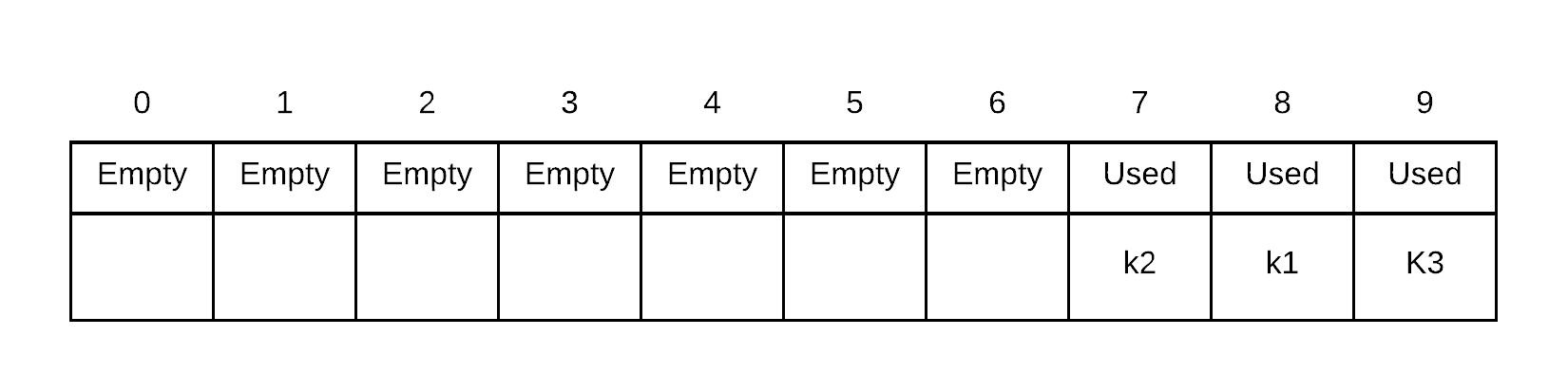
Insert k1 to k3 (no collisions, so they go to their hash indices)
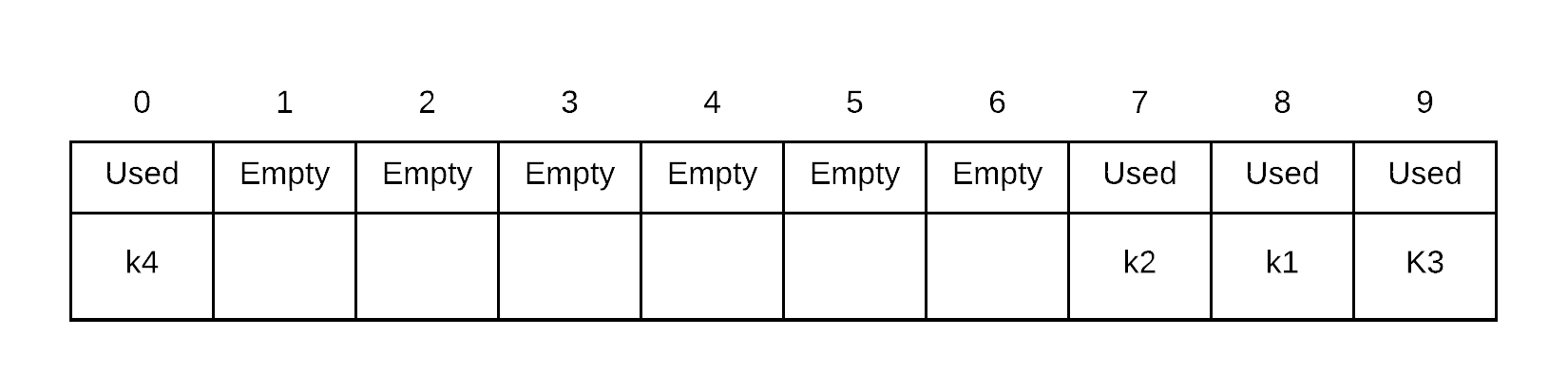
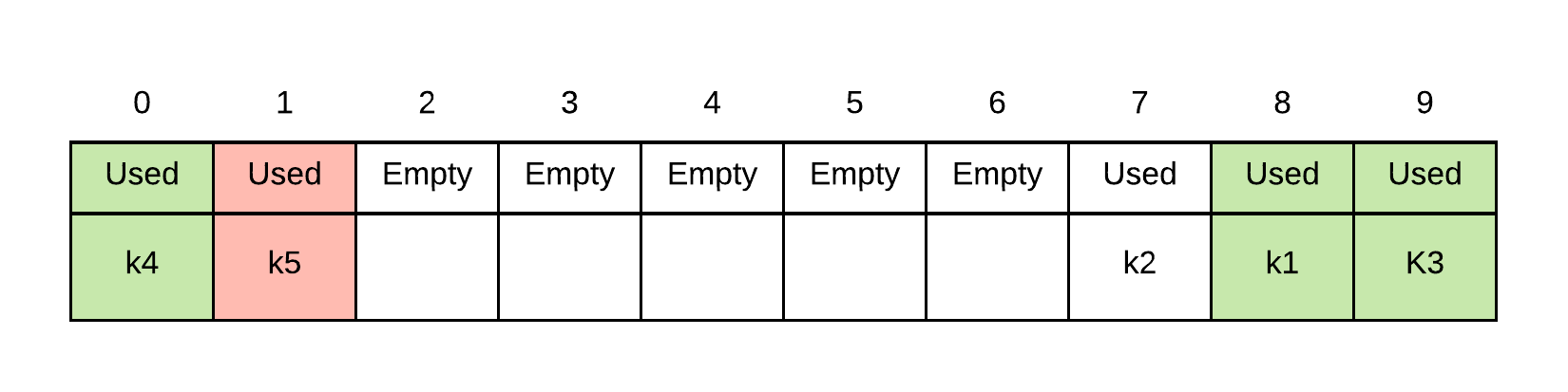
Insert k4. probe sequence of k4 is . Thus, we place k4 into index 0 because 7, 8 and 9 are all occupied
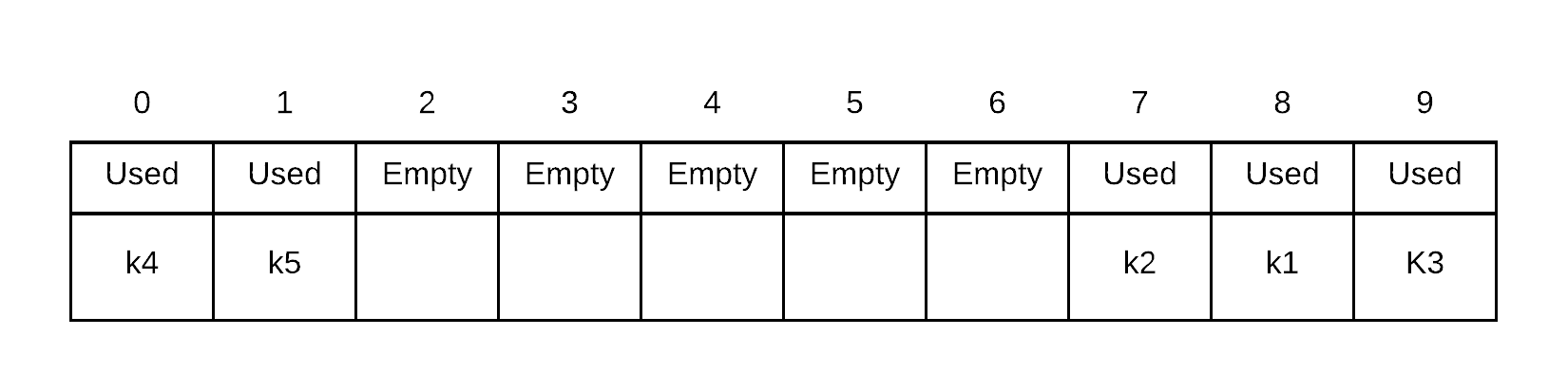
Insert k5. probe sequence of k5 is . Thus, we place k5 into index 1 because 8, 9 and 0 are all occupied
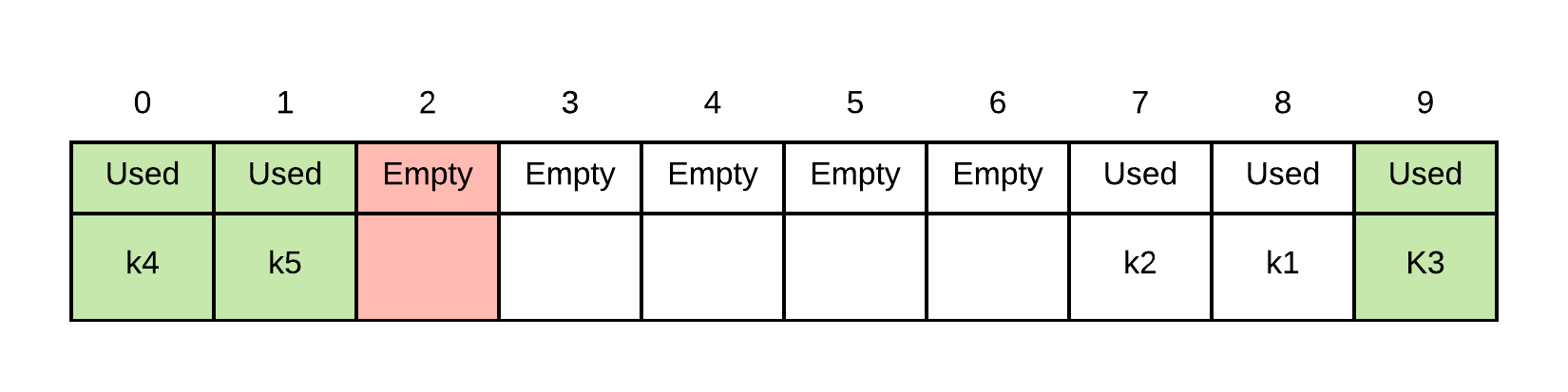
Suppose we then decided to do a search. First lets search for something that isn't there, k6. k6's probe sequence is: . We begin looking at the first probe index. We proceed until we get to index 2. Since index 2 is empty, we can stop searching
If we were to search for something that is there (k5 for example), here is what we would do. Probe sequence for k5 is . Thus, we would start search at 8, we would look at indices 8,9,0, and 1. At index 1 we find k5 so we stop
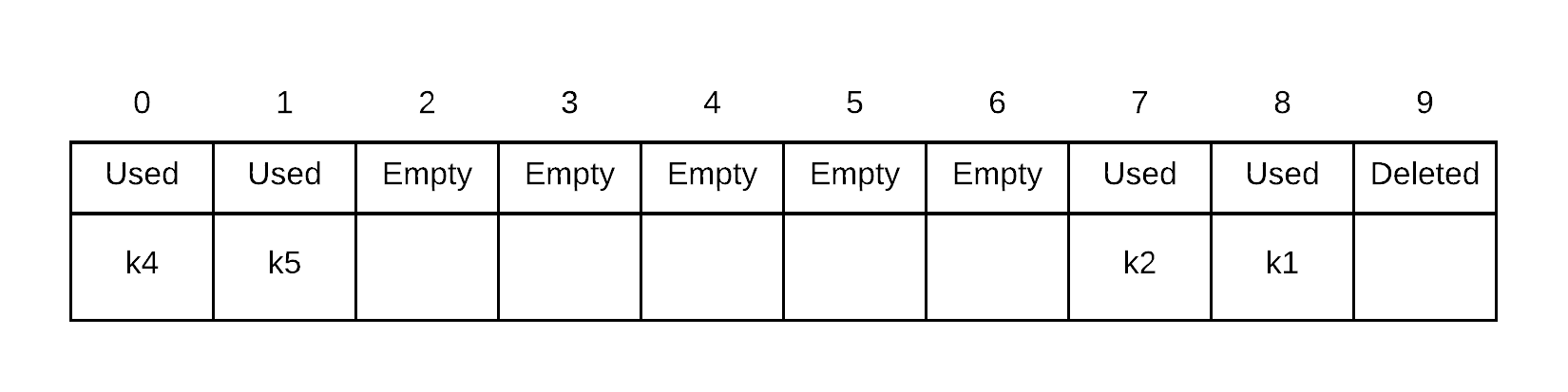
Suppose we delete k3. All we need to do is find it, and mark the spot as deleted
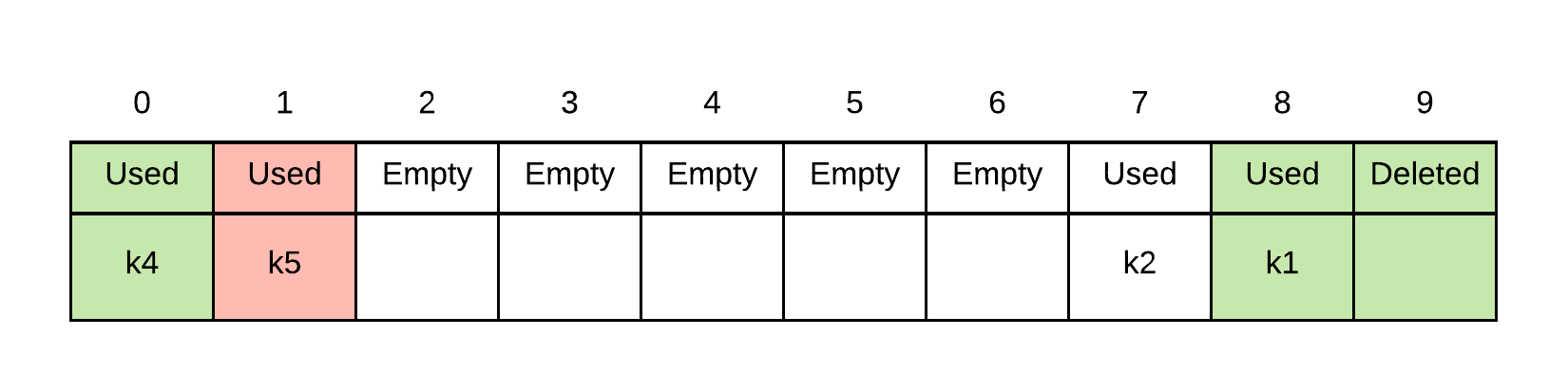
When a spot is deleted, we still continue when we search... thus if we were to look for k5, we do not stop on deleted, we must keep going.
Quadratic Probing
With linear probing everytime two records get placed beside each other in adjacent slots, we create a higher probability that a third record will result in a collision (think of it as a target that got bigger). One way to avoid this is to use a different probing method so that records are placed further away instead of immediately next to the first spot. In quadratic probing, instead of using the next spot, we use a quadratic formula in the probing sequence. The general form of this algorithm for probe sequence i is: . At it's simplest we can use . Thus, we can use:
| Key | Hash index |
|---|---|
| k1 | 8 |
| k2 | 7 |
| k3 | 9 |
| k4 | 7 |
| k5 | 8 |
| k6 | 9 |
Quadratic Probing Example
Insert k1 to k3 (no collisions, so they go to their hash indices)
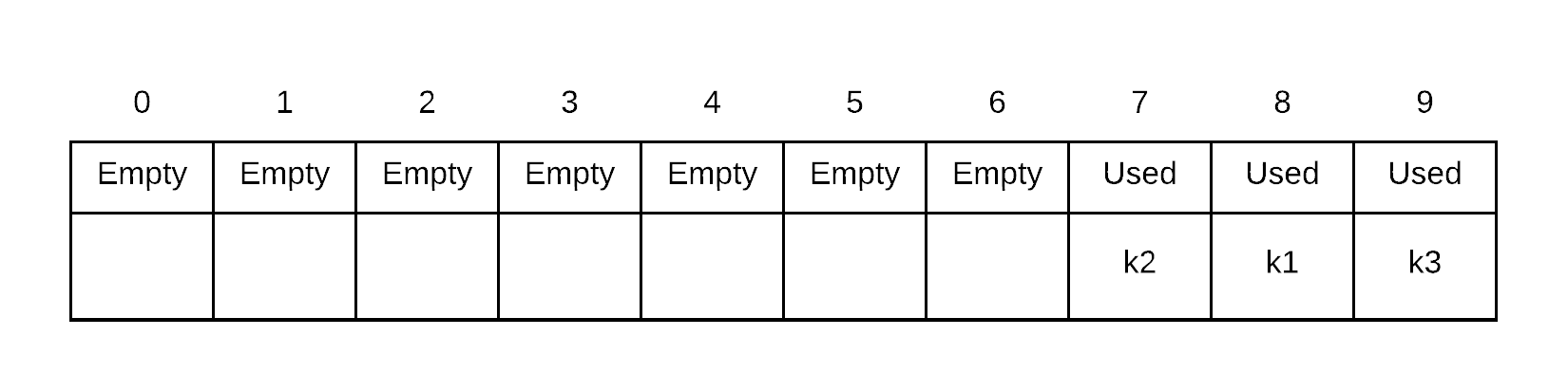
Insert k4. probe sequence of k4 is . Thus, we place k4 into index 1 because 7 and 8 are both occupied
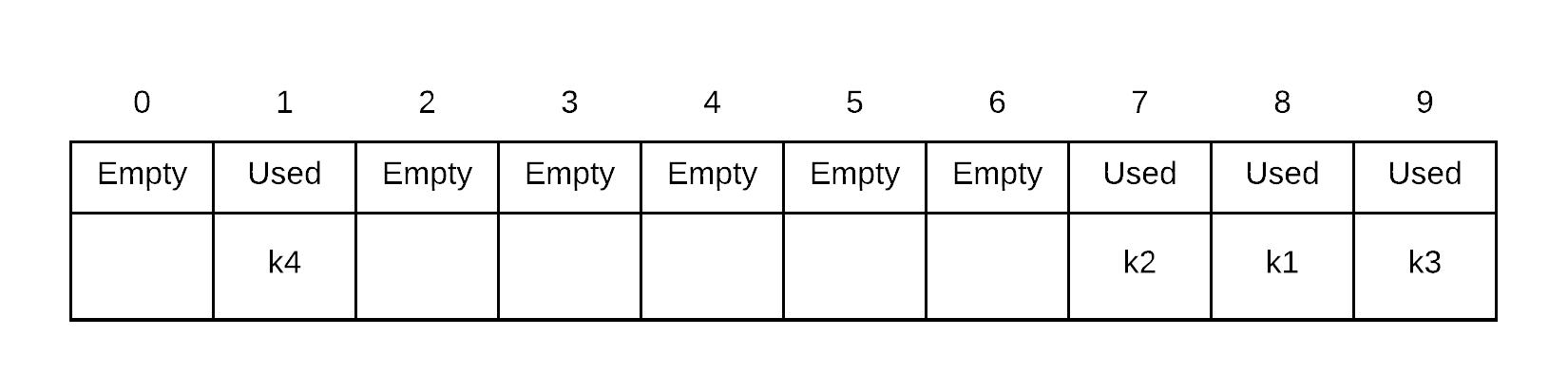
Insert k5. probe sequence of k5 is . Thus, we place k5 into index 2 because 8 and 9 are both occupied
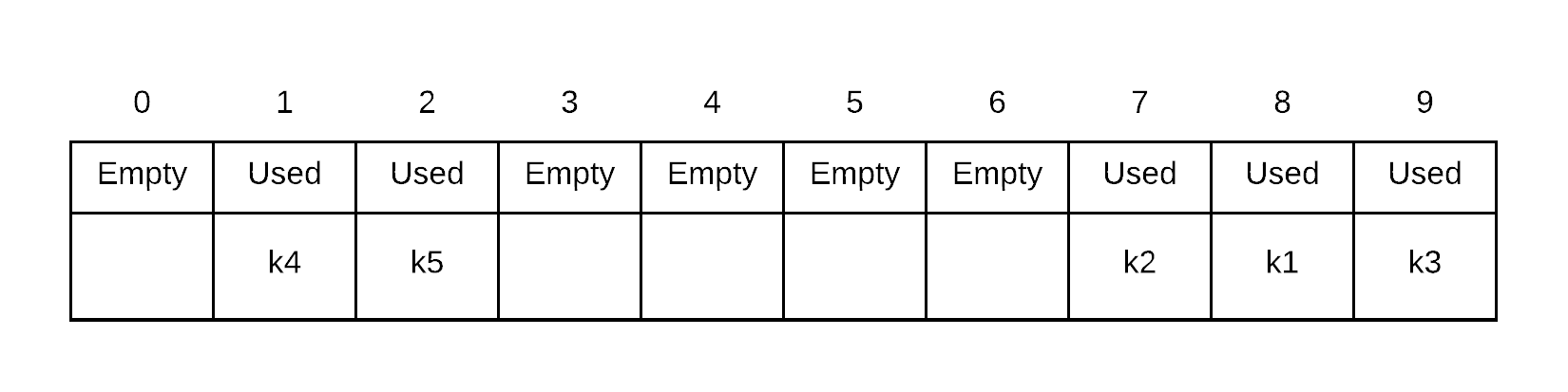
Likewise searching involves probing along its quadratic probing sequence. Thus, searching for k6 involves the probe sequence . We search index 9, then index 0. We can stop at this point as index 0 is empty
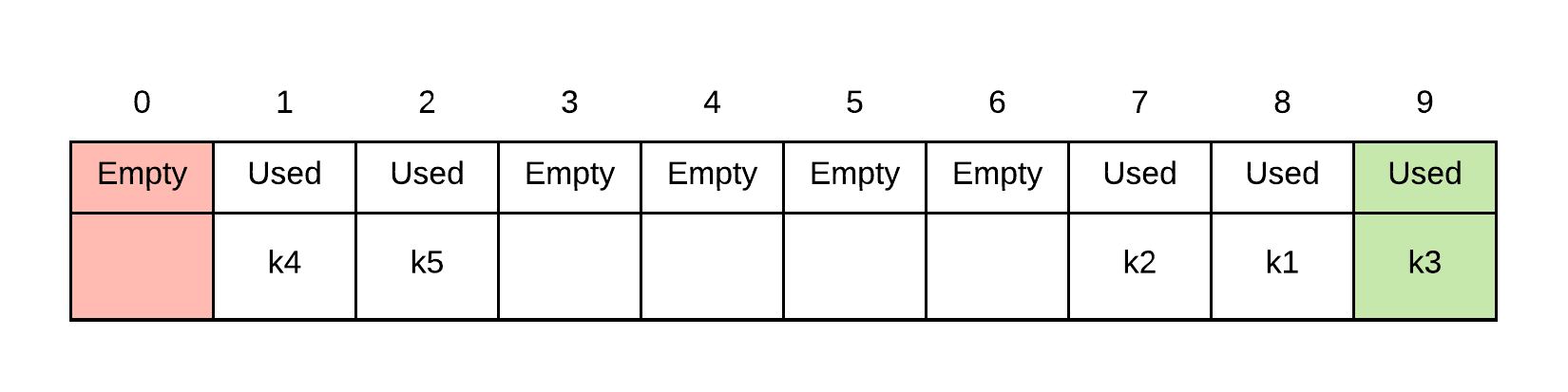
Double Hashing
Double hashing addresses the same problem as quadratic probing. Instead of using a quadratic sequence to determine the next empty spot, we have 2 different hash functions, and . We use the first hash function to determine its general position, then use the second to calculate an offset for probes. Thus the probe sequence is calculated as:
| Key | Hash1(key) | Hash2(key) |
|---|---|---|
| k1 | 8 | 6 |
| k2 | 7 | 2 |
| k3 | 9 | 5 |
| k4 | 7 | 4 |
| k5 | 8 | 3 |
| k6 | 9 | 2 |
Double uses a second hash function to calculating a probing offset. Thus, the first hash function locates the record (initial probe index)... should there be a collision, the next probe sequence is a hash2(key) away.
Again we start off with hashing k1, k2 and k3 which do not have any collisions
Insert k4. probe sequence of k4 is . Thus, we place k4 into index 1 because 7 was occupied
Insert k5. probe sequence of k5 is . Thus, we place k5 into index 4 because 8 and 1 were occupied